
Jørgen Ringen





In this post, we’ll look at some common patterns for managing data in a distributed microservice architecture. Managing data in a monolithic application is fairly easy and well understood, but in a microservice architecture it can be a lot more challenging and different patterns are needed. By just re-using patterns from the monolithic world we often end up with poor results and this anti-pattern is often known as the “distributed monolith”.
Each microservice manages their own data in private data-stores. Every piece of data is owned by a single service. When a service needs to exchange data with other services it calls their public api by using REST, gRPC, etc. Designing stable, reusable and encapsulated API’s are crucial.
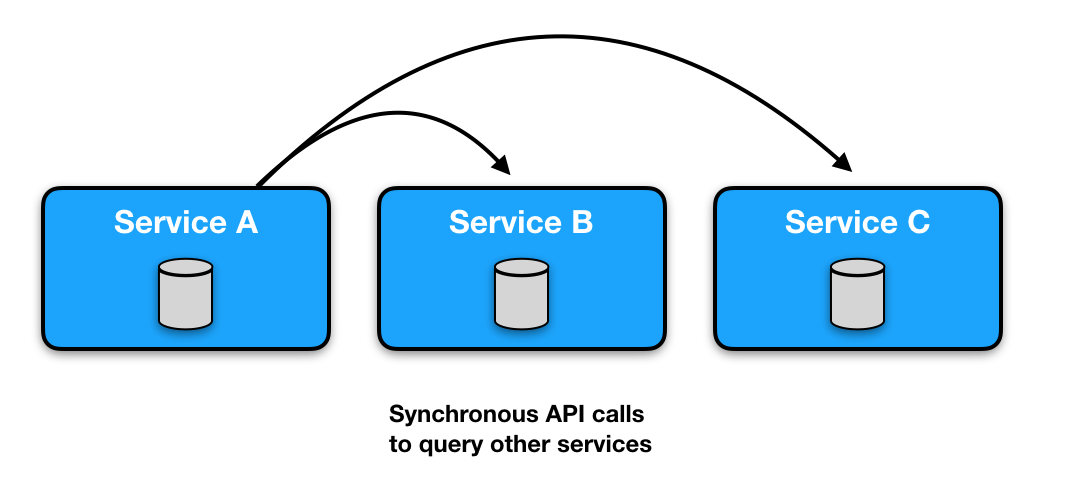
Pros
Cons
Each microservice manages their own data in private data-stores. Every piece of data is owned by a single service, but data can be replicated across services as reference-data. Each microservice stores the necessary reference-data it needs in an optimized data structure. Services can publish business events when state changes by the use of message-oriented middleware (ActiveMQ, RabbitMQ, Kafka, etc) so that the other services can update their reference-data accordingly in an asynchronously manner. The events will typically include an event-type plus data describing what has happened. This pattern is often referred to as event-driven architecture.
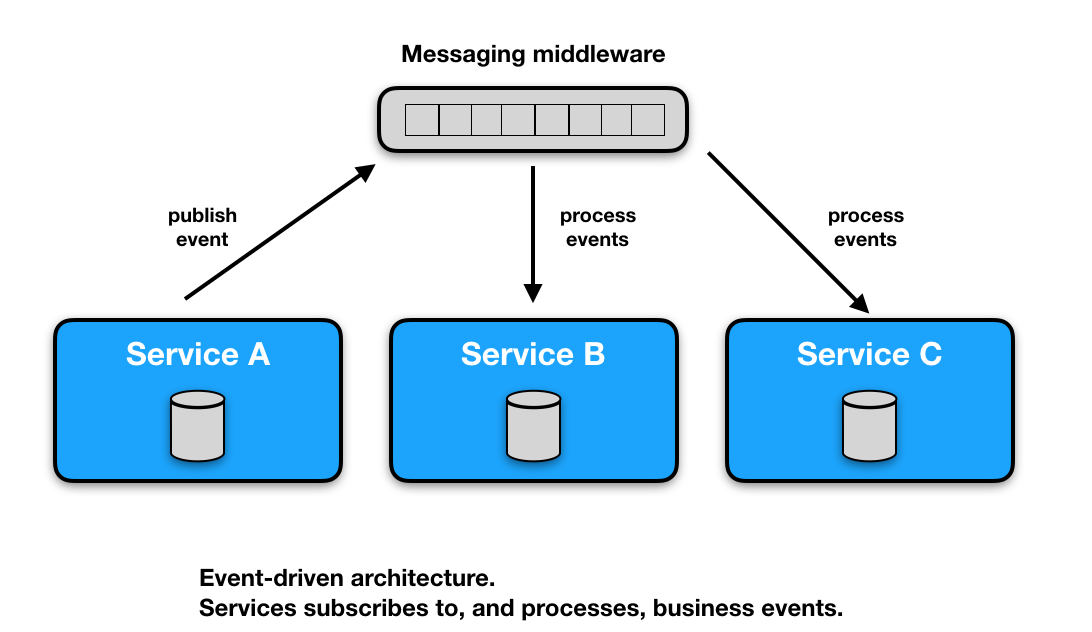
Pros
Cons
This pattern is somewhat similar to “private data-store, async events”, but it reduces the need for storing data locally in the services. Services publishes business events to an event-store. Services can subscribe to, and process, events or they can do queries directly towards the event store. This pattern is often used in conjunction with CQRS. There are some very interesting technologies emerging in this field, like KSQL which is a query language for Kafka.
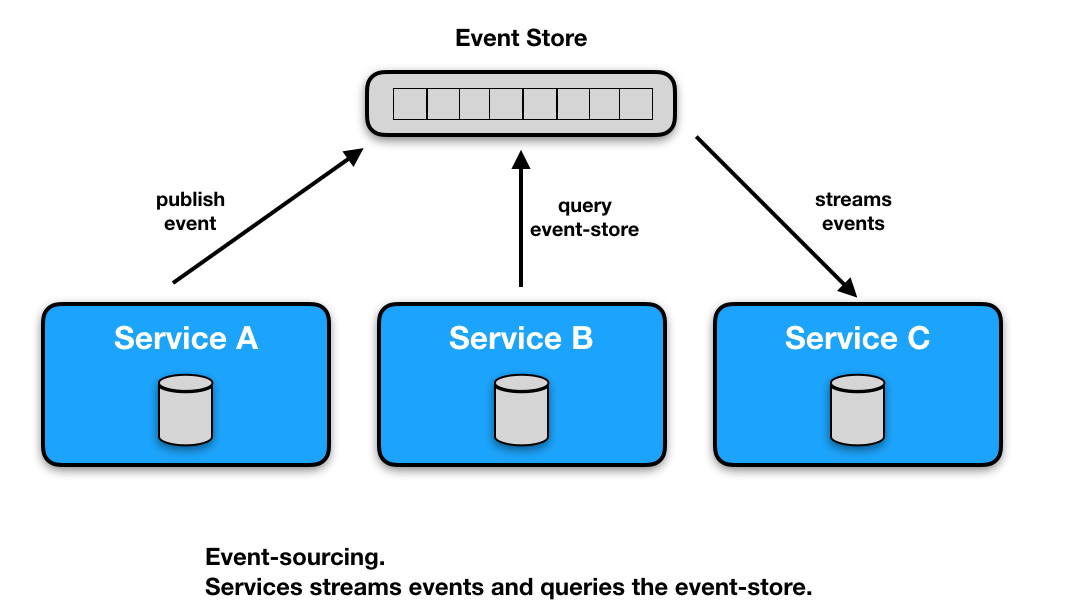
Pros
Cons
This is an old but useful pattern, even in a distributed microservice world. Read-only and immutable metadata is stored in libraries and used by the different microservices. Examples: Countries, states, colours, etc.
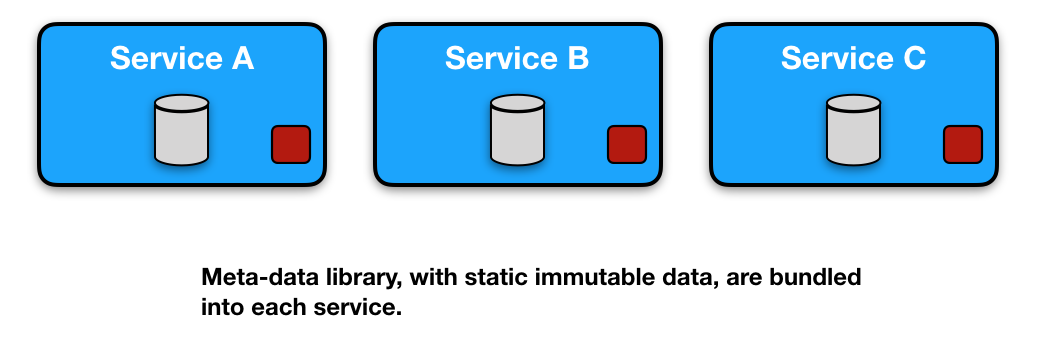
Pros
Cons
As always there’s no silver bullet when it comes to managing data in microservices and software architecture is an evolutionary process as well. It’s important to choose the right tools for the job and different use-cases requires different patterns. Some data needs some degree of synchronous communication and some data fits more closely with asynchronous communication. It’s highly likely that you’ll find data in both categories, and data that’s somewhere in between, in every software system. Each of the patterns can easily be used in conjunction with each other.
One thing that’s certain is that you have to have a bigger toolbox in the microservice-world and things like events and asynchronous communication should definitely be first-class citizens in that toolbox.
This post was inspired by a great talk by Randy Shoup at QCon New York 2017: Managing data in microservices